Kimi K2.6: Coding AgénticoA Escala de Producción
Kimi K2.6 es el modelo de coding agéntico listo para producción: diseñado para ejecuciones autónomas de 12 horas, coordinación de 300 agentes en enjambre y generación full-stack. SWE-Bench Pro 58,6%, Terminal-Bench 2.0 66,7%.
Basado en el backbone K2 MoE de un billón de parámetros con contexto de 262K tokens y compresión automática. Compatible con la API de Anthropic, disponible en Kimi.com, API y Kimi Code CLI. Validado por Vercel, Factory.ai y CodeBuddy.
Experiencia Kimi K2.6
Prueba el asistente de IA poderoso de inmediato
¡Kimi K2.6 ya está disponible! 🎉 Puedo ejecutarme durante 12 horas seguidas, coordinar hasta 300 subagentes y manejar codebases completos de extremo a extremo. ¿Qué quieres construir hoy?
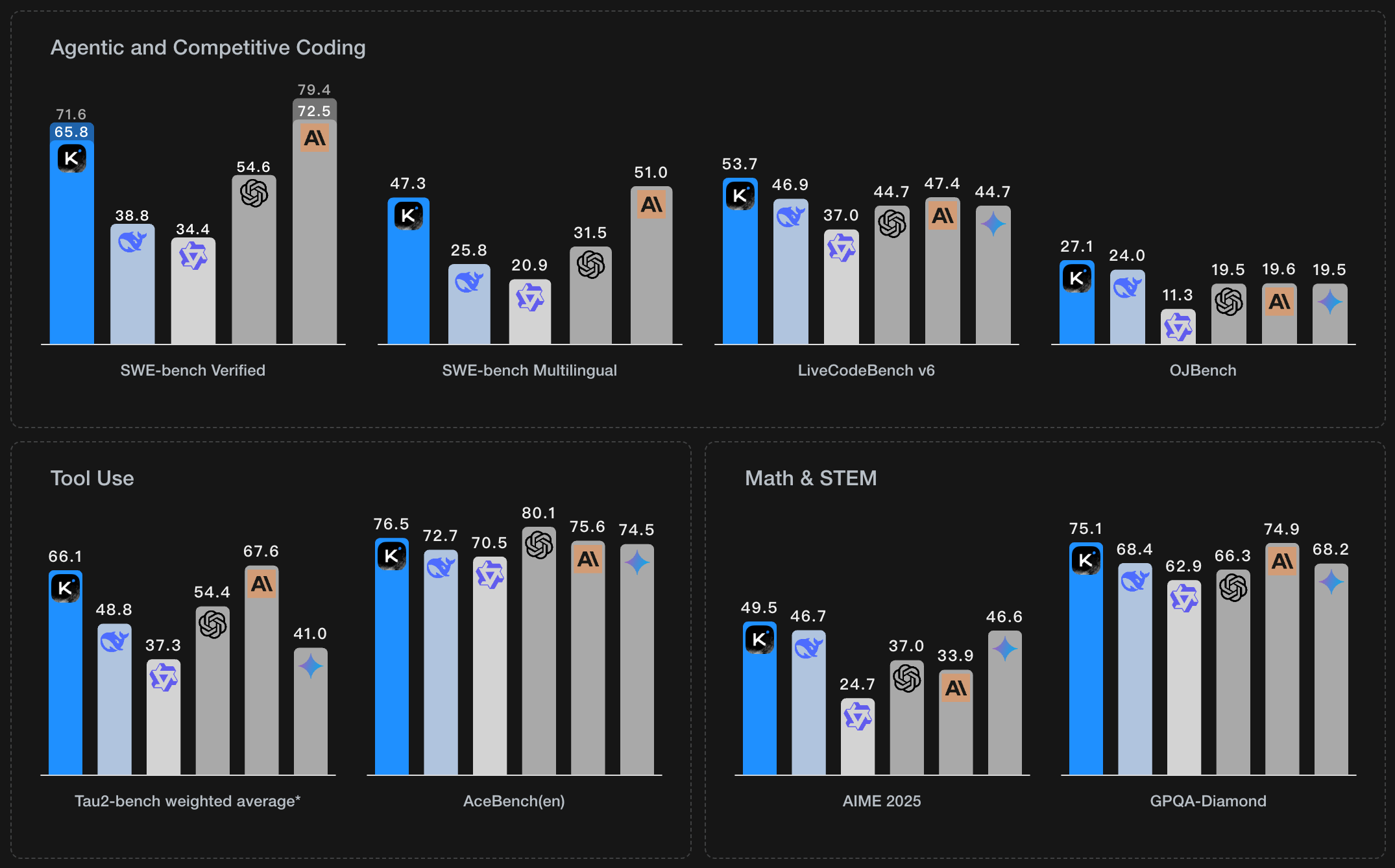
Rendimiento Líder en Todos los Benchmarks
Kimi K2.6 logra resultados de nivel producción en benchmarks de coding, razonamiento y matemáticas
Capacidades Agénticas
Resolución autónoma de problemas con interacción de herramientas
Alto Rendimiento
Razonamiento y programación de vanguardia
Mezcla de Expertos
384 expertos con 32B parámetros activados
Versiones
Compara K2.6 con las paginas actuales de Kimi Code
Sigue desde K2.6 hacia K2.7, Kimi Code y el estado de proximas versiones.
Kimi K3
Hub insignia: especificaciones 2.8T, contexto 1M, API kimi-k3, precio y cuándo cambiar.
ContinuarKimi K2.7 Code
Resumen de la version actual, capacidades y contexto practico de K2.7 Code.
ContinuarKimi Code
Rutas de configuracion, notas de API y flujos de trabajo para desarrolladores.
ContinuarEstado de Kimi K3
Disponibilidad de K3 con docs oficiales de Kimi Code y notas de plan.
ContinuarKey Features of Kimi K2.6
Production-grade agentic coding capabilities built for 12-hour autonomous runs, 300-agent swarms, and full-stack generation.
What is Kimi K2.6?
Kimi K2.6 is MoonshotAI's production agentic coding model — the first in the K2 series designed for 12-hour autonomous runs and 300-agent swarm coordination. It keeps the trillion-parameter MoE backbone while adding a new execution layer purpose-built for long-horizon engineering tasks.
About Kimi K2.6
Kimi K2.6 is the general-availability release of MoonshotAI's agentic coding model, shipped April 21 2026 after an eight-day preview. It is built on the same trillion-parameter Mixture-of-Experts backbone as the original K2 (1T total / 32B active / 384 experts, MLA attention, SwiGLU, MuonClip training) but adds a production execution layer optimized for sustained autonomous operation.
The headline capability is duration and coordination: K2.6 can hold a coding task together for twelve hours and 4,000 coordinated steps across up to 300 sub-agents in a single swarm. Its 262K token context window — paired with automatic compression that summarizes and elides history as sessions grow — means a mid-sized monorepo plus its test output fits in context without truncation-induced drift at hour nine.
Three reference deployments shipped with the GA release: a Zig-based inference runtime reaching 193 tokens/sec, a 185% throughput improvement on the exchange-core financial matching engine, and full-stack Next.js generation validated by Vercel at >50% improvement on their internal benchmark. K2.6 is available on Kimi.com, the official API, and the Kimi Code CLI.
K2.6 Technical Specs
- • 262K token context with auto-compression
- • 300 sub-agents per swarm, 4,000+ step coordination
- • SWE-Bench Pro 58.6% / Terminal-Bench 2.0 66.7%
- • MathVision 93.2% (with Python tool use)
- • Anthropic API compatible, Apache 2.0 base
K2.6 Use Cases
- • Long-horizon autonomous coding (12h+ runs)
- • Full-stack generation: UI → auth → database
- • Performance engineering on unfamiliar codebases
- • Multi-agent swarm orchestration (up to 300 agents)
- • Systems programming (Zig, Rust, low-level runtimes)
What Developers Say About K2.6
Engineering teams share their experience running K2.6 in production for long-horizon agentic coding tasks.
"We ran K2.6 against our internal Next.js benchmark and saw over 50% improvement versus K2.5. It handles App Router, Server Components, and the surrounding ecosystem without hallucinating APIs — that gap has been open for a long time."
"K2.6 improved 15% on both our evaluated benchmarks. The swarm orchestration is the real unlock — decomposing a large refactor across 50 workers and reconciling the outputs coherently is something we haven't seen from any other model at this scale."
"12% better code generation accuracy and 18% better long-context stability versus K2.5. For our users doing multi-file refactors, the stability improvement is the one that actually matters — fewer sessions that drift off-track at step 200."
"Deployed Qwen3.5-0.8B locally in Zig using K2.6. It picked Zig without prompting — a language with a tiny training corpus — and still produced a working low-level runtime at 193 tokens/sec. That's the frontier I care about."
"Handed K2.6 the exchange-core matching engine and asked for throughput improvements. It read the Java codebase, identified hot paths, and rewrote them correctly — 185% median throughput, no broken invariants. I reviewed the plan, not the diffs."
"The design-to-code capability is genuinely new. I gave it a Figma export and a database schema; it generated the animated UI, wired up auth, and connected the database. What used to be a three-day sprint is now a three-hour K2.6 run."
"K2.6 is the first model where "give it to the agent overnight" stopped being aspirational. We handed it a 60k-line Java codebase, asked it to find and fix throughput bottlenecks, and woke up to a 185% improvement with no regressions. That's not a demo — that's production."
Kimi K2.6 FAQ
Answers to common questions about Kimi K2.6's capabilities, benchmarks, and how to get started.
Need technical support?
Access documentation, community support, and technical resources for Kimi K2.6.
K2 base model (Apache 2.0): HuggingFace • GitHub • API Documentation